


@inproceedings{didolkar2025ctrlo,
title={CTRL-O: Language-Controllable Object-Centric Visual Representation Learning},
author={Didolkar, Aniket Rajiv and Zadaianchuk, Andrii and Awal, Rabiul and Seitzer, Maximilian and Gavves, Efstratios and Agrawal, Aishwarya},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2025}
}CVPR 2025
CTRL-O: Language-Controllable Object-Centric Visual Representation Learning
1Mila - Quebec AI Institute,
2Université de Montréal,
3University of Amsterdam,
4University of Tübingen,
5Archimedes/Athena RC, Greece
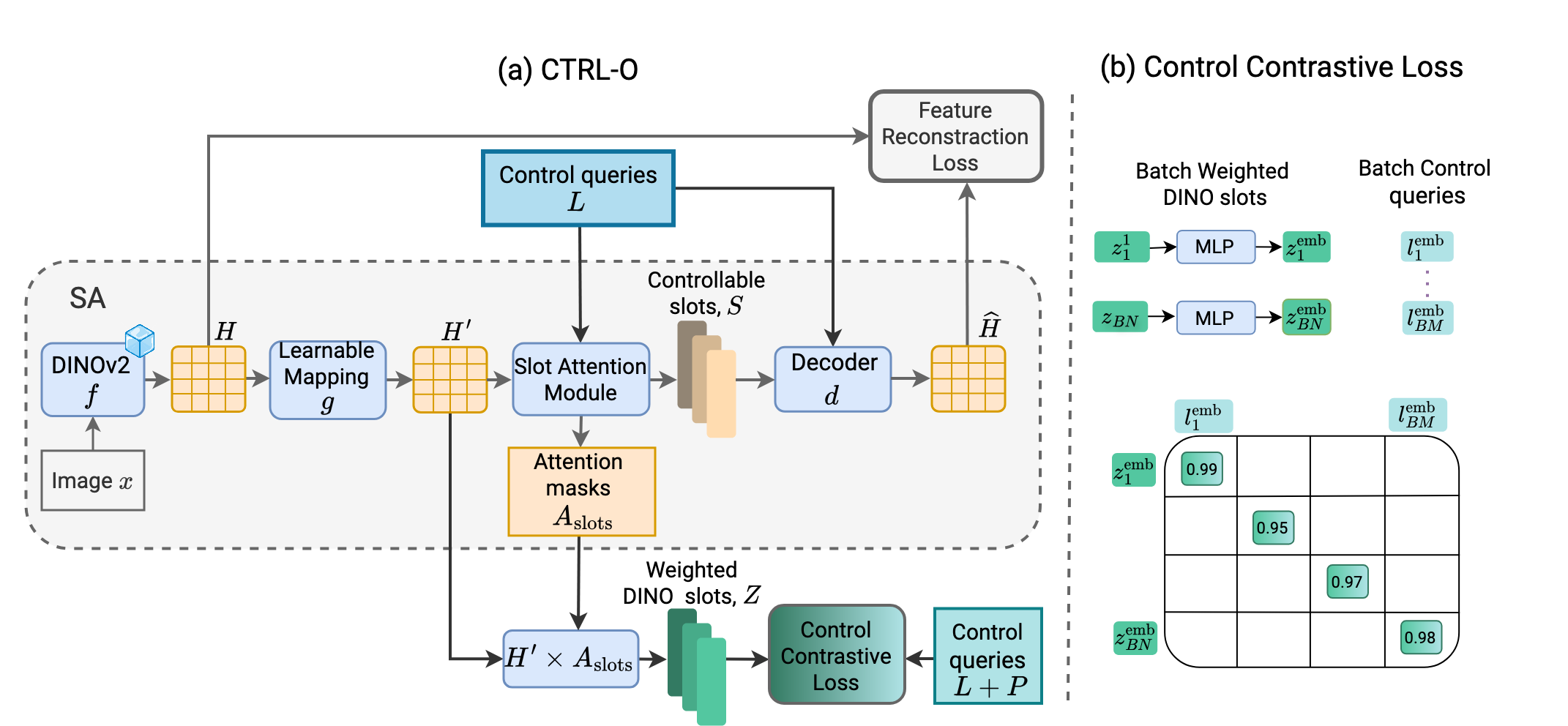
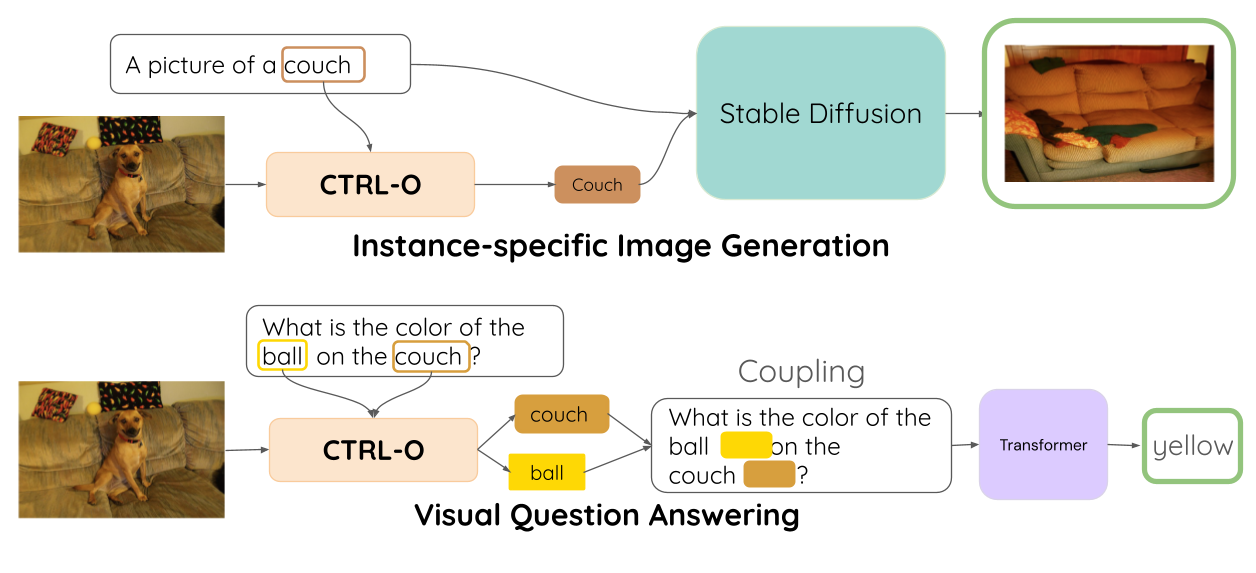
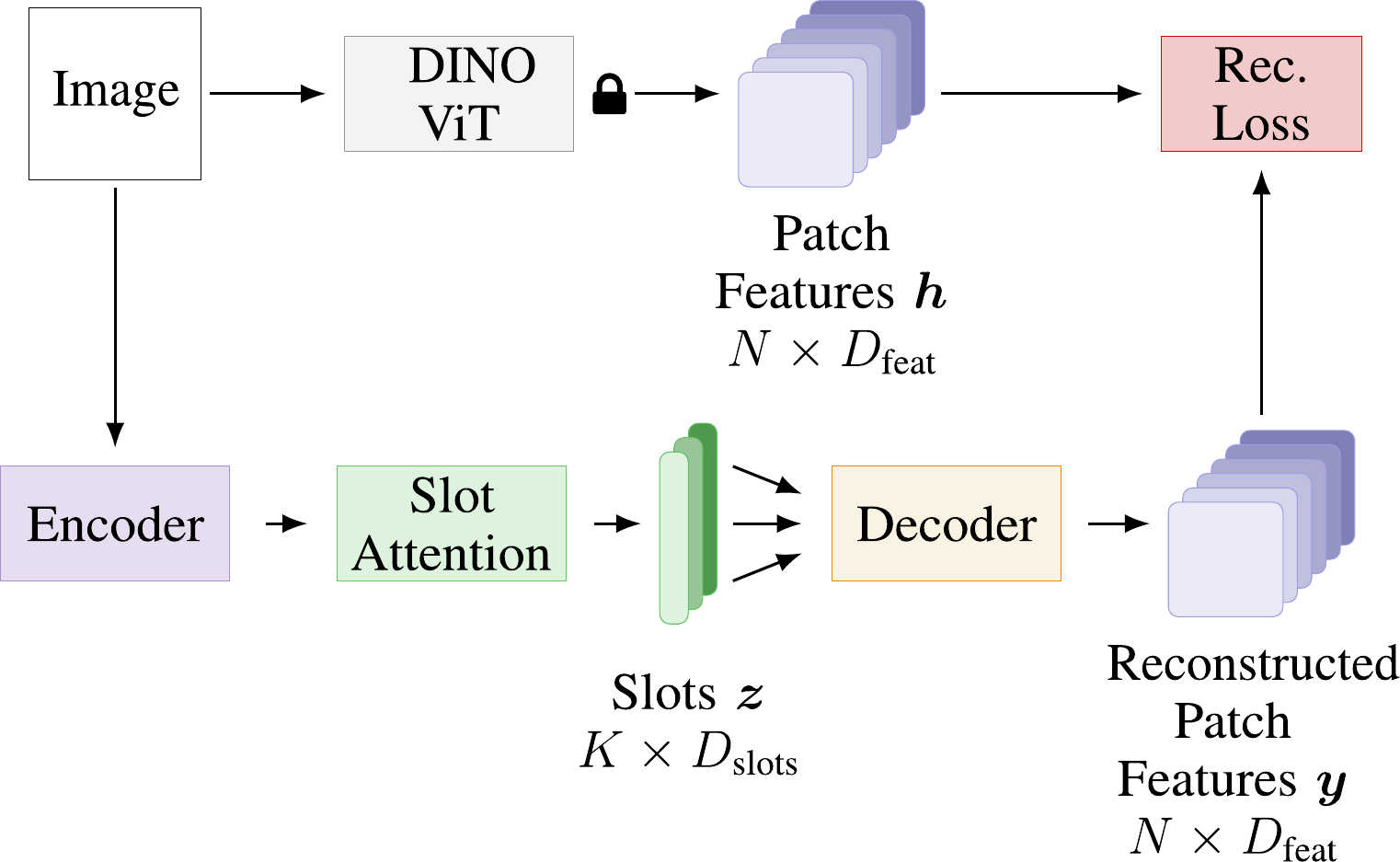
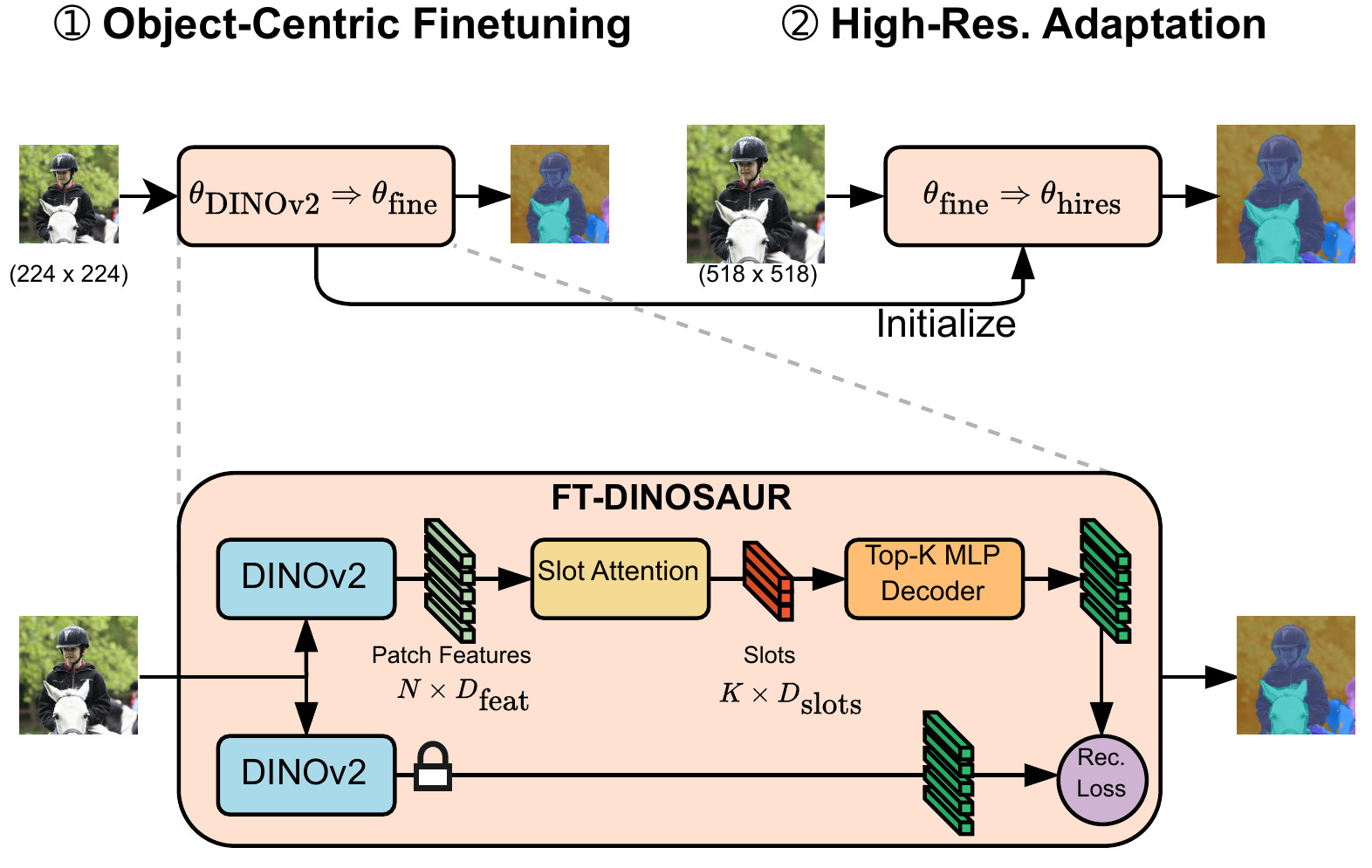
Object-centric representation learning aims to decompose visual scenes into fixed-size vectors called "slots" or "object files", where each slot captures a distinct object. CTRL-O introduces language-based control, enabling specific object targeting and multimodal applications, and achieves strong results on downstream tasks such as text-to-image generation and visual question answering.
*Equal contribution
†Equal advising
